列を操作する関数は値をオブジェクトにくるんで受け取るといいかもしれない
一つテクニックを思いついたので書いてみます。
…まあ大した話じゃないですし、もっといい方法が知られているのかもしれません。考えを整理するという意味でメモしておきます。
さて、次のようなド単純なインターフェイスを用意しておきます。
// F# type IRef<'a> = abstract Value : 'a
// C# interface IRef<T> { T Value { get; } }
値をこのインターフェイスにくるんで受け取るようにすると良いことがあるよ、というお話です。
特に、何らかの列からある条件に合致するものだけを取り出す、みたいな関数が対象です。ここでは例として、整数の列を「偶数だけを取り出して昇順にソートする」関数を考えてみます。次のように定義できるでしょう。
// F# let toSortedEvens1 (items : int seq) = items |> Seq.filter (fun item -> item % 2 = 0) |> Seq.sort
// C# static IEnumerable<int> ToSortedEvens1( this IEnumerable<int> items ) { return items.Where( item => item % 2 == 0 ).OrderBy( item => item ); }
何の問題もないように見えますが、この関数にもう少し汎用性を持たせたいのです。例として次のようなクラスがあるとしましょう。
// F# type Hoge (piyo : int) = member this.Piyo = piyo
// C# class Hoge { public readonly int Piyo; public Hoge( int piyo ) { this.Piyo = piyo; } }
この Hoge 型オブジェクトの列を「Piyoプロパティが偶数のものだけを取り出して昇順にソート」したい場合に、先ほど定義した toSortedEvens1 関数は利用できるでしょうか。いえ、残念ながら出来ません。先ほどの関数では int の列が返って来るだけですが、今回は Hoge の列が結果として欲しいのです。
もちろん Hoge 型を受け取る関数を定義しなおせば良いのですが、その設計はイマイチだと思います。関数型プログラミングではデータを出来るだけ不変な(immutableな)値として扱うことが推奨されます。それにしたがって考えると、システム全体を「不変な値を扱う下位レイヤー」と「可変なオブジェクトを扱う上位レイヤー」の2層に大きく分けて捉えた時、出来るだけ下位レイヤーが厚くなるようにするべきです。今回の例ですと、Hoge クラスは可変で上位レイヤーに属するクラスかもしれません。しかし「偶数だけを取り出して昇順にソート」というロジックは下位レイヤーに押し込めてしまいたいところです。
そこで、これを少し書き換えて int の列ではなく IRef<int> の列を受け取るように修正してみます。
// F# let toSortedEvens2 (items : #IRef<int> seq) = items |> Seq.filter (fun item -> item.Value % 2 = 0) |> Seq.sortBy (fun item -> item.Value)
// C# static IEnumerable<T> ToSortedEvens2<T>( this IEnumerable<T> items ) where T : IRef<int> { return items.Where( item => item.Value % 2 == 0 ).OrderBy( item => item.Value ); }
このように int 列を直接操作するのではなく IRef<int> にくるんで操作するようにすれば、一段抽象化が行われていることになりますので先ほどの問題を解決することが出来ます。
もっとも単純な方法は、Hoge クラスに IRef<int> インターフェイスを実装してしまうことです。もちろんそれでも問題は解決するのですが、代わりに Hoge クラスの定義が汚染されてしまいますので望ましくないケースも考えられます。ここでは Hoge クラスを汚染しないアプローチを考えてみます。
まず準備として、次のようなモジュール(C#は static class)を定義しておきましょう。
// F# module Ref = type Sourced<'src, 'value> = { Source : 'src; Value : 'value } with interface IRef<'value> with member this.Value = this.Value let inline sourced src value = { Source = src; Value = value } let inline ofSource mapper src = { Source = src; Value = mapper src } let inline toSource ref = ref.Source let inline value (ref : #IRef<_>) = ref.Value
// C# static class Ref { public class Sourced<TSource, TValue> : IRef<TValue> { public readonly TSource Source; public readonly TValue Value; public Sourced(TSource src, TValue value) { this.Source = src; this.Value = value; } TValue IRef<TValue>.Value { get { return this.Value; } } } public static Sourced<TSource, TValue> OfSource<TSource, TValue>( TSource src, TValue value ) { return new Sourced<TSource, TValue>( src, value ); } }
これらを利用して、Hoge オブジェクトの列を「Piyoの値が偶数のものだけを取り出して昇順にソート」してみたいと思います。
// F# let items = [3; 5; 2; 9; 7; 0; 8; 6 ] |> List.map (fun item -> Hoge item) let newItems = items |> Seq.map (Ref.ofSource (fun hoge -> hoge.Piyo)) // #IRef<int> に変換 |> toSortedEvens2 // 偶数のものだけを取り出して昇順にソート |> Seq.map Ref.toSource // Hoge に戻す |> Seq.toList
// C# var items = Array.ConvertAll( new[] { 3, 5, 2, 9, 7, 0, 8, 6 }, item => new Hoge( item ) ); var newItems = items .Select( h => Ref.OfSource( h, h.Piyo ) ) .ToSortedEvens2() .Select( r => r.Source ) .ToArray();
いかがなものでしょう?
個人的には使える場面は結構あるんじゃないかと思っているのですが…。
追記
Twitter で「セレクタ使えば十分では」というご指摘を頂きました。つまりこういうことですね。
let toSortedEvens3 selector items = items |> Seq.filter (fun item -> (selector item) % 2 = 0) |> Seq.sortBy (fun item -> (selector item))
むむ、この簡単な例では確かにその通りなのですが・・・。
この関数が実際はもっと複雑な関数で、他の関数へも selector を引き回さないといけない場合とかを考えると、インターフェイスに括りだすほうがシステムの構造をうまく表現するという場面もあるんじゃないかなぁ…と思ってみたり。あるいは、同じようなセレクタ関数を受け取る関数が沢山必要になる場合は、インターフェイスに括りだすほうが全体として見たときシンプル、みたいな場面を想像しています。
あとは selector の中身が重たい処理になる場合とか。。。
もうちっと考えてみます。
追記2
@igeta さんがオブジェクト式を利用して書きなおしてくれました。ありがとうございます!
https://gist.github.com/igeta/9183923
オブジェクト式、面白いですね!私も今後機会があったら使っていきたいです。そしてアクティブパターンの使い方にも目からウロコが落ちました。そうかーこういう使い方もできるんですね。アクティブパターンは無理矢理使ってみたことはあるものの、まだイマイチ使いこなせていないです…。
immutable な配列クラス作ってみた #fsharp
需要あるのか分からないけど、カッとなって作った。昨晩作り始めて、先ほど出張帰りの新幹線で完成。テストはしていないッ(キリッ
名前は迷ったんだけど、あまり長い名前にしたくなかったので Immutarray というちょっと変な名前(勝手な造語)にした。ImmutableArray だと immutable collections と被るみたいだし。心のなかでは「イミュータレイ」って読んでる。
コピペしてご自由にお使いください。名前等、気に食わなければ好きなように変更してどうぞ。
※ よく分からず inline 付けまくってみたけどいいんかいな?
namespace (好きな名前を入れてね) open System type private ImmutarrayData<'a> = { RawArray : 'a[] } type Immutarray<'a when 'a : equality> (rawArray : 'a[]) = let data = { RawArray = rawArray } member inline private this.Data = data member this.Length = data.RawArray.Length member this.Item with get i = data.RawArray.[i] member this.__RAW_ARRAY__ = data.RawArray member this.ToArray() = Array.copy data.RawArray member this.Equals (x : Immutarray<'a>) = (data :> IEquatable<_>).Equals x.Data override this.Equals x = match x with :? Immutarray<'a> as x -> this.Equals x | _ -> false override this.GetHashCode () = data.GetHashCode() interface IEquatable<Immutarray<'a>> with member this.Equals x = this.Equals x interface seq<'a> with member this.GetEnumerator() = (data.RawArray :> 'a seq).GetEnumerator() interface Collections.IEnumerable with member this.GetEnumerator() = data.RawArray.GetEnumerator() [<Sealed; AbstractClass; Runtime.CompilerServices.Extension>] type Immutarray = static member inline private Raw (array : Immutarray<_>) = array.__RAW_ARRAY__ static member ForEach (array, action) = Array.ForEach (Immutarray.Raw array, action) static member ConvertAll (array, converter) = Immutarray (Array.ConvertAll (Immutarray.Raw array, converter)) static member Exists (array, predicate) = Array.Exists (Immutarray.Raw array, predicate) static member TrueForAll (array, predicate) = Array.TrueForAll (Immutarray.Raw array, predicate) static member Find (array, predicate) = Array.Find (Immutarray.Raw array, predicate) static member FindIndex (array, predicate) = Array.FindIndex (Immutarray.Raw array, predicate) static member FindLast (array, predicate) = Array.FindLast (Immutarray.Raw array, predicate) static member FindLastIndex (array, predicate) = Array.FindLastIndex (Immutarray.Raw array, predicate) static member FindAll (array, predicate) = Immutarray(Array.FindAll (Immutarray.Raw array, predicate)) static member IndexOf (array, value) = Array.IndexOf (Immutarray.Raw array, value) static member LastIndexOf (array, value) = Array.LastIndexOf (Immutarray.Raw array, value) static member BinarySearch (array, value) = Array.BinarySearch (Immutarray.Raw array, value) static member BinarySearch (array, value, comparer) = Array.BinarySearch (Immutarray.Raw array, value, comparer) static member BinarySearch (array, index, length, value) = Array.BinarySearch (Immutarray.Raw array, index, length, value) static member BinarySearch (array, index, length, value, comparer) = Array.BinarySearch (Immutarray.Raw array, index, length, value, comparer) [<Runtime.CompilerServices.Extension>] static member ToImmutarray source = Immutarray (Seq.toArray source) [<CompilationRepresentation( CompilationRepresentationFlags.ModuleSuffix ); RequireQualifiedAccess>] module Immutarray = let inline private raw (a : Immutarray<'a>) = a.__RAW_ARRAY__ let inline ofArray array = Immutarray array let inline ofList list = Array.ofList list |> ofArray let inline ofSeq source = Array.ofSeq source |> ofArray let inline toArray array = Array.copy (raw array) let inline toList array = Array.toList (raw array) let inline toSeq array = Array.toSeq (raw array) let inline length array = raw array |> Array.length let inline get (array : Immutarray<'a>) index = array.[index] let inline empty<'a when 'a : equality> = Immutarray<'a> [||] let inline init count initializer = Array.init count initializer |> ofArray let inline create count value = Array.create count value |> ofArray let inline zeroCreate count = Array.zeroCreate count |> ofArray let inline map mapping array = Array.map mapping (raw array) |> ofArray let inline mapi mapping array = Array.mapi mapping (raw array) |> ofArray let inline map2 mapping array1 array2 = Array.map2 mapping (raw array1) (raw array2) |> ofArray let inline mapi2 mapping array1 array2 = Array.mapi2 mapping (raw array1) (raw array2) |> ofArray let inline collect mapping array = Array.collect mapping (raw array) |> ofArray let inline filter predicate array = raw array |> Array.filter predicate |> ofArray let inline choose chooser array = raw array |> Array.choose chooser |> ofArray let inline rev array = raw array |> Array.rev |> ofArray let inline sort array = raw array |> Array.sort |> ofArray let inline sortBy projection array = raw array |> Array.sortBy projection |> ofArray let inline sortWith comparer array = raw array |> Array.sortWith comparer |> ofArray let inline permutate indexMap array = raw array |> Array.permute indexMap |> ofArray let inline sub array startIndex count = Array.sub (raw array) startIndex count |> ofArray let inline iter action array = Array.iter action (raw array) let inline iteri action array = Array.iteri action (raw array) let inline iter2 action array1 array2 = Array.iter2 action (raw array1) (raw array2) let inline iteri2 action array1 array2 = Array.iteri2 action (raw array1) (raw array2) let inline isEmpty array = Array.isEmpty (raw array) let inline forall predicate array = Array.forall predicate (raw array) let inline exists predicate array = Array.exists predicate (raw array) let inline forall2 predicate array1 array2 = Array.forall2 predicate (raw array1) (raw array2) let inline exists2 predicate array1 array2 = Array.exists2 predicate (raw array1) (raw array2) let inline max array = Array.max (raw array) let inline min array = Array.min (raw array) let inline sum array = Array.sum (raw array) let inline average array = Array.average (raw array) let inline maxBy projection array = Array.maxBy projection (raw array) let inline minBy projection array = Array.minBy projection (raw array) let inline sumBy projection array = Array.sumBy projection (raw array) let inline averageBy projection array = Array.averageBy projection (raw array) let inline fold folder state array = Array.fold folder state (raw array) let inline foldBack folder array state = Array.foldBack folder (raw array) state let inline fold2 folder state array1 array2 = Array.fold2 folder state (raw array1) (raw array2) let inline foldBack2 folder array1 array2 state = Array.foldBack2 folder (raw array1) (raw array2) state let inline reduce reduction array = Array.reduce reduction (raw array) let inline reduceBack reduction array = Array.reduceBack reduction (raw array) let inline scan folder state array = Array.scan folder state (raw array) |> ofArray let inline scanBack folder array state = Array.scanBack folder (raw array) state |> ofArray let inline find predicate array = Array.find predicate (raw array) let inline findIndex predicate array = Array.findIndex predicate (raw array) let inline tryFind predicate array = Array.tryFind predicate (raw array) let inline tryFindIndex predicate array = Array.tryFindIndex predicate (raw array) let inline pick chooser array = Array.pick chooser (raw array) let inline tryPick chooser array = Array.tryPick chooser (raw array) let inline append array1 array2 = Array.append (raw array1) (raw array2) |> ofArray let inline concat arrays = arrays |> Seq.map raw |> Array.concat |> ofArray let inline partition predicate array = let a1, a2 = Array.partition predicate (raw array) in Immutarray a1, Immutarray a2 let inline zip array1 array2 = Array.zip (raw array1) (raw array2) |> ofArray let inline zip3 array1 array2 array3 = Array.zip3 (raw array1) (raw array2) (raw array3) |> ofArray let inline unzip array = let a1, a2 = Array.unzip (raw array) in Immutarray a1, Immutarray a2 let inline unzip3 array = let a1, a2, a3 = Array.unzip3 (raw array) in Immutarray a1, Immutarray a2, Immutarray a3 [<CompilationRepresentation( CompilationRepresentationFlags.ModuleSuffix ); RequireQualifiedAccess>] module Array = let toImmutarray = Immutarray.ofArray let ofImmutarray = Immutarray.toArray [<CompilationRepresentation( CompilationRepresentationFlags.ModuleSuffix ); RequireQualifiedAccess>] module List = let toImmutarray = Immutarray.ofList let ofImmutarray = Immutarray.toList [<CompilationRepresentation( CompilationRepresentationFlags.ModuleSuffix ); RequireQualifiedAccess>] module Seq = let toImmutarray = Immutarray.ofSeq let ofImmutarray = Immutarray.toSeq [<CompilationRepresentation( CompilationRepresentationFlags.ModuleSuffix ); RequireQualifiedAccess>] module Set = let ofImmutarray (array : Immutarray<_>) = Set.ofArray array.__RAW_ARRAY__ let toImmutarray set = Immutarray (Set.toArray set) [<CompilationRepresentation( CompilationRepresentationFlags.ModuleSuffix ); RequireQualifiedAccess>] module Map = let ofImmutarray (array : Immutarray<_>) = Map.ofArray array.__RAW_ARRAY__ let toImmutarray map = Immutarray (Map.toArray map)
F# と設計について考えてみた #FsAdventJP
F# Advent Calendar 2013 15日目の記事です。
ヘタレなので大したことは書けないです。初めての Advent Calendar でやや緊張気味。
ステートレスとステートフル
現在 F# を実戦投入してます。OpenGL を利用した 3D CAD 系アプリケーションの受託開発です。WPFによるスタンドアロンなデスクトップアプリケーションとなります。下図のような構成となっています。

ViewModel を C# にしたのは深い意味はないです。ViewModel は F# による恩恵が大きい部分ではないだろうという判断と、いきなり全面的に F# にするのに私がビビっただけです。次の機会には ViewModel も F# にするかもしれません。
さて、作っていく過程で気づいたのですが、Model部分は更に次のような2層に別れる感じです。

関数型プログラミングでは状態を持たない(ステートレスな)データ構造や関数が推奨されますが、そうはいってもアプリケーションは操作すれば状態変化を起こしますから、どこかでその状態を管理しなくてはなりません。ですから図のような層に別れるのは当然の帰結だったと言えます。(が、私は実際に使ってみて初めて気づいた(^^;)
多くのバグは状態遷移に起因します。この対策として、状態を持たない不変な値と関数をベースにプログラムを組み立てようというのが関数型、状態変数を隠蔽して状態遷移を局所化しようというのがオブジェクト指向、と分類できるでしょうか。(これは矮小化した捉え方かもしれませんが)
- 関数型「バグるなら 不変にしよう ホトトギス」
- オブジェクト指向「バグるなら 隠蔽しよう ホトトギス」
(ホトトギス関係ない)
F# は関数型的な文法とオブジェクト指向的な文法の両方を備えているので、最初は使い分けに迷いました。上記のようなステートレス/ステートフルな層を意識するようになって以来、迷いが少し解消しました。
出来るだけステートフルな層が薄く設計して、状態管理を局所化すると良い感じです。ステートレスな部分は INotifyPropertyChanged インターフェイスの実装が不要ですから、MVVMもやりやすくなります。ステートフルなコードは、実行時に取り得る状態やその遷移を脳内でイメージしないと読み書きできないので大変です。つまりロジックだけでなく時間軸のイメージも必要になるということです。これに対してステートレスなコードは、動的な時間軸のイメージは必要とされません。ステートレスな構造や関数群からは、時が止まった静謐な印象を受けます(個人の感想です)。
まとめると、
- ステートレスな層とステートフルな層に分けて考える
- ステートレスな層は関数型のスタイルで
- ステートフルな層はオブジェクト指向のスタイルで
- 出来るだけステートフルな層を薄くする(状態管理を局所化する)
- ステートレスな層にはロジックを書く
- ステートフルな層には状態遷移を書く(ロジックは出来るだけステートレスな層に追い出す)
- ステートフルな層もリアクティブプログラミング(よく分かってませんが)な感じで出来るだけ宣言的に書く
という方針がいいんじゃないかなあ、というのが現時点での感想です。
型の種類と粒度
F# には型の種類が色々あって最初は混乱します。整理のために表にまとめてみました。
| 型 | 代入 | 比較 | 変更 |
|---|---|---|---|
| struct | deep copy | value equality | stateless |
| record/union | shallow copy | value equality | stateless |
| class | shallow copy | reference equality | ? |
…とまとめてみたものの、この表のようにスッキリと割り切れるかというと実際はそうでもありません。例えばレコード型は mutable なメンバーも定義できてしまうし(基本的に使っちゃダメだと私は思ってますが)、クラスの比較は Equals 等のオーバーライドによって value equality にすることも出来ます。その辺を端折ってザックリまとめちゃうと、だいたいこの表のような感じになるかなと思っています。
ステートフルな型を定義したい場合はクラスの一択だと私は思います。しかし逆は真ではなく、クラスだからといってステートフルとは限りません。ですので上記の表では ? マークにしてあります。実際、F# を使っていると状態の変更操作を一切持たないステートレスなクラスを定義する機会は非常に多いですし、むしろ積極的にステートレスな設計を目指すべきと思います。
ですから、ここでは class をステートレスなものとステートフルなものに分けてみましょう。大雑把に考えて、粒度の小さな型から大きな型の純に並べると次のようになるのではないでしょうか。
| type | stateless | value equality | deep copy |
|---|---|---|---|
| struct | ○ | ○ | ○ |
| record/union | ○ | ○ | - |
| stateless class | ○ | - | - |
| stateful class | - | - | - |
レコードにするべきかクラスにするべきか、それが問題だ
これが分からなくて、是非 F#er の皆さんのご意見を伺ってみたいと思っているところです。
先ほど、ステートレスとステートフルの二層に分かれると書きました。つまり上の表の "stateless class" と "stateful class" の間に境界があるように思います。
struct < record/union < stateless class <<<(超えられない壁)<<< stateful class
※ 型の位置づけ上
構造体(struct)とレコードの使い分けはあまり迷いません。大抵はレコードにしておけばOKです。構造体を使う時は、例えば外部のネイティブのAPIにデータを渡したい時とか、巨大な配列に格納して unsafe コードで高速にアクセスしたいとか、そういう具体的な理由があるときです。それ以外はレコードで問題無いと思います。ですので以下の議論から構造体は外します。
さて、上で stateless と statefull の間に(超えられない壁)を書きましたが、F# の文法上はレコードとクラスの間に壁があります。
record/union <<<(超えられない壁)<<< stateless class < stateful class
※ F#の文法上
どうも迷うのがレコードと stateless class の使い分けです。レコードで定義していた型に変更が入ると、割と面倒なことになる印象があります。特にレコードをクラスに変更する事案が発生すると割と泣けます。
- レコードにメンバを追加すると、レコードのインスタンスを生成している部分全てに変更が入ります。デフォルトは None でいいんだけどなー、というメンバの追加でもデフォルト値の設定は出来ません。もちろん常に { defaultValue with Hoge = ... } と初期化する習慣がある賢者なら困らないのでしょうけど(そうするべきなのかな?)
- 同様に、何らかの事情でレコードをクラスに変更するとインスタンスを生成している部分は全て修正が必要になります。
- 更に、レコードとクラスでは型推論の効き方が違います。レコードなら hoge.Piyo と書いておくと Piyo プロパティを持つレコード型に推論してくれますが、クラスの場合はこの推論が効きません(理由は知らない…)。ですので、かたっぱしから明示的な型の指定を追加する必要が生じます。
レコードをクラスに変更するなどということ自体が、私がレコードとクラスの使い分けが出来ていない証拠なのかもしれません。レコードが表現するのは「データ」、クラスが表現するのは「(振る舞いによって抽象化された)オブジェクト」とうまく使い分ければ良いのでしょうけれど、なかなか現実はうまくいきません。データとしての性格が強いと判断してレコードで定義した型に、後から「ちょっとコンストラクタで初期化処理を追加したいな」と考えるだけで、クラスに変更する必要が生じるのです。
つまり、「データを表す型」と「振る舞いを表す型」の間を仕切る明確な区切りは(本質的には)存在しないように思うのです。しかし F# ではレコードとクラスの間に文法上の大きな開きがあるために、このような問題が発生するのだと思います。
以上を考えると、レコード型の使用は低いレイヤーに限定しておいて乱用を避けたほうが良いのかもしれません。つまり、十分にプリミティブなデータ構造でこの先変更が入ることはまず考えられないデータ型であるとか、特定のモジュールの内部でのみ使用される private なデータ型などに使用を限定するべきなのかもしれません。
しかし、レコード型のシンプルで明快な文法はあまりに誘惑が大きく、つい使いたくなってしまいます。レコード型との上手な付き合い方、ご教授下さい><
Equals と等号にまつわるエトセトラ【余談】
obj の比較
ここからは余談です。比較演算について C# との違いがあることを知ったので、メモがてら書いておきます。
まずは C# のコードから。
var s1 = new String( new[] { 't', 'e', 's', 't' } ); var s2 = new String( new[] { 't', 'e', 's', 't' } ); Console.WriteLine( object.ReferenceEquals( s1, s2 ) ); // false Console.WriteLine( s1 == s2 ); // true Console.WriteLine( ((object)s1) == ((object)s2) ); // false!!!
string 型には == 演算子がオーバーロードされていますが、object 型にキャストして == 演算子で比較すると参照の比較になってしまいます。(鉄板ネタですね)
同様のコードを F# で試してみます。
let s1 = String( [| 't'; 'e'; 's'; 't' |] ) let s2 = String( [| 't'; 'e'; 's'; 't' |] ) printfn "%A" (obj.ReferenceEquals( s1, s2 )) (* false *) printfn "%A" (s1 = s2) (* true *) printfn "%A" ((s1 :> obj) = (s2 :> obj)) (* true!!! *)
obj にキャストされた状態でもきちんと値で比較されます。F# の比較演算子はきちんと Equals を呼び出してくれるのですね。C# とは違うのだよ、C# とは。
配列の比較
では今度は配列の比較について調べてみましょう。
let array1 = [| 1; 2; 3 |] let array2 = [| 1; 2; 3 |] printfn "%A" (obj.ReferenceEquals( array1, array2 )) (* false *) printfn "%A" (array1.Equals array2) (* false *) printfn "%A" (array1 = array2) (* true *)
配列は Equals は参照比較で、等号は値比較となっています。これはギョッとしますが、Equals は .NET Framework 側で決まっている挙動なのでやむを得ないでしょう。むしろ等号を無理に値比較にしないほうが良かったんじゃないかと思ってみたり思わなかったり、うーむ。ちなみに list は等号も Equals も値比較となっています。
では次のように配列をレコードのメンバに含めるとどうなるでしょうか。
type ArrayRec = { Array : int array }
この場合は ArrayRec は Equals も等号も共に値比較となります。
インターフェイスの比較
等値演算子(等号)は Equals を呼び出すと書きました。ですのでインターフェイスでも等号で値比較ができます。
(* こんなインターフェイスを定義して… *) type IHoge = abstract Piyo : int module Hoge = (* private なレコード型にインターフェイスを実装して… *) type private HogeImpl = { Piyo : int } with interface IHoge with member this.Piyo = this.Piyo (* インスタンス生成関数 *) let create piyo = { Piyo = piyo } :> IHoge (* 値の等しい2つのインスタンスを生成して… *) let hoge1 = Hoge.create 123 let hoge2 = Hoge.create 123 (* IHoge 型でも演算子で値の比較ができる! *) printfn "%A" (hoge1 = hoge2) (* true *)
レコード型は Equals のオーバーロードが暗黙的に行われますので、自分でコードを書かなくても値比較ができます。しかも Equals を明示的に呼び出すことなく等号で値比較が出来るのです。F#er にとっては「当たり前じゃん」という話かもしれません。しかし C# にどっぷり染まっていた私としてはインターフェイスは参照比較という固定観念がありましたので、これには少なからず驚きました。
このスタイルで書いておけば実装の詳細を隠蔽(カプセル化)した値型が定義できる、ような、んーあんまり意味無いような…。
ただこのままでは comparison 制約を満たしません。次のように IComparable を継承させるだけで comparison 制約は実現できます。
type IHoge = inherit IComparable (* これを追加 *) abstract Piyo : int
レコード型では Equals と同様に IComparable も暗黙的に実装されますので、自分で比較演算を実装する必要はありません。これは便利ですね。
しかしこれは注意点があります。IHoge を実装する別のクラスがあると破綻してしまうのです。
(* IHoge の別の実装 *) module YetAnotherHoge = type private HogeImpl = { PiyoPiyo : int } with interface IHoge with member this.Piyo = this.PiyoPiyo (* インスタンス生成関数 *) let create piyopiyo = { PiyoPiyo = piyopiyo } :> IHoge let hoge1 = Hoge.create 123 let hoge2 = YetAnotherHoge.create 123 printfn "%A" (hoge1 < hoge2) (* InvalidCastException!!! *)
コンパイルは通ります。しかし実行してみると、残念ながら InvalidCastException で落ちてしまいます。異なる型で大小の序列が付けられるはずがありませんから、これは当然の結果ですね。安易な IComparable の継承は避けたほうが良さそうです。
最後に
F# はいいですねー。関数型のディープな話題には全くついていけないヘタレですが、使っていて気持ち良いです。みんなもっと使いましょー!
(※ ところで弊社ではエンジニア募集中です。興味ある方は @u_1roh まで。 モノコミュニティ | 採用情報)
F# の Set と HashSet のパフォーマンス
ハマったのでメモしておきます。
経験的には、要素の追加/削除などの処理は F# の Set よりも HashSet の方が速いです。F# の Set は binary tree だと思うので(ですよね?)これらの計算量は O(log n)、対して HashSet は O(1) なので、まあそうだよね、と思います。
しかし、実務のコードで HashSet がエラく遅くて F# の Set に置き換えたら高速になったケースがあったので、テストコードを書いてみました。
open System open System.Collections.Generic open System.Diagnostics [<EntryPoint>] let main argv = let size = 100000 (* 10万要素 *) (* F# の Set と HashSet のパフォーマンス比較。 集合が空になるまで先頭要素の削除を繰り返す処理。*) (* ---- F# Set ---- *) do let watch = Stopwatch() watch.Start() let mutable collection = seq { 1 .. size } |> Set.ofSeq while not collection.IsEmpty do collection <- collection |> Set.remove (collection |> Seq.head) printfn "F# Set : elapsed = %A" watch.Elapsed (* ---- HashSet ---- *) do let watch = Stopwatch() watch.Start() let collection = HashSet<int>( seq { 1 .. size } ) while collection.Count > 0 do collection |> Seq.head |> collection.Remove |> ignore printfn "HashSet : elapsed = %A" watch.Elapsed 0
実行結果:
F# Set : elapsed = 00:00:00.2876429 HashSet : elapsed = 00:00:10.7875533
HashSet 激遅ですね。
どうも先頭要素を取り出す処理(collection |> Set.head の部分。LINQで書くなら collection.First())が遅いみたいです。とはいっても先頭要素の取得が必ず遅いわけではなく、遅くなってしまう条件があるようです。上記のプログラムでは取り出した先頭要素は毎回 Remove されていますから、毎回取り出される先頭要素が異なります。このような場合に先頭要素の取得に時間がかかるようです。
HashSet の要素の列挙ってどういう実装になっているんでしょう。ヘタレなのであんまり分かりませんが、確かにハッシュテーブルは要素の検索には向いていても列挙には向かなそうです。先頭要素が削除されてしまうと、ハッシュテーブルから先頭要素を探索する処理が必要になるから遅いのかな?
(…ここまで書いて気づきましたが、この記事ってたまたま比較対象に F# の Set を使っただけで、F# は殆ど関係ないですね。まあいいか。)
.NET 4.0 の場合 FSharp.Core が色々と謎
教えてエライ人~(ToT)
謎現象に悩まされて会社の同僚と一緒にハマっております。何か Visual Studio がややこしいことになってる気がします。
出来るだけ状況を整理して書いてみますが、正直なところ混乱しているのでうまく整理できる自信なし。あと、同僚と一緒に調べているので必ずしも僕が自分で確認した現象だけではないのでその点も悪しからず。
F#のプロジェクト作成 → FSharp.Core 4.3.0.0 を参照している
- Visual Studio 2012 で
- .NET Framework 4.0 の
F# プロジェクトを作ったとします。
参照設定を確認すると、参照している FSharp.Core のバージョンは 4.3.0.0 です。
FSharp.Core 4.3.0.0 を開発で使用するには .NET 4.5 が必要
こうして作成したモジュール(アセンブリ)を共同開発しているお客様にお渡ししました。お客様の開発環境は
- Visual Studio 2010
- .NET Framework 4.0 (4.5はインストールされていない)
- 開発言語はC#(F#は使用しない)
というものでした。ここで問題が発生しました。
Visual Studio 2010 の参照設定に、FSharp.Core 4.3.0.0 に依存したモジュールが追加できないのです。「それは .NET アセンブリではありません」的なエラーが出て読み込めませんでした。
結論として、お客様の開発環境に .NET Framework 4.5 をインストールして頂いたところ問題が解消しました。
箇条書きで整理:
- そのお客様には、VS2010 でビルドした FSharp.Core 4.0.0.0 に依存したモジュールを渡したことがあり、その時は問題なく動作していた。こちらの環境を VS2012 にアップグレードし、FSharp.Core 4.3 に依存するようになったところで問題が発生した。
- .NET のターゲットを 4.0 でビルドしたにも関わらず、開発環境に .NET 4.5 が必要とされた。
- 実行環境には .NET 4.5 は要求されない様子。.NET 4.0 のみの仮想マシン環境で実行モジュールは動作した。
どうも不思議な動作なので、「FSharp.Core は 4.3 をやめて 4.0 にダウングレードするほうが無難かも」と思ったのですが・・・次々と謎現象にぶつかりよく分からないことになっております。
FSharp.Core を参照から外してもコンパイル出来る、が・・・
参照設定から FSharp.Core を削除してもコンパイルできてしまいます。F#プロジェクトは自動的にFSharp.Coreが参照されるような仕掛けが何か動いているのでしょうか。まあ、それはそれでいいんですが・・・。
何故か Seq.where を使っている箇所があるとコンパイルエラーになります。代わりに Seq.filter を使えばコンパイルが通ります。
Seq.where は Seq.filter のシノニムで、FSharp.Core 4.3.0.0 から追加された関数のようです。オブジェクトブラウザで確認すると、FSharp.Core 4.0.0.0 の SeqModule には Where が含まれませんが、4.3.0.0 には Where が含まれていることが分かります。
ということは、参照先が FSharp.Core 4.3.0.0 から 4.0.0.0 に変わってしまったということでしょうか。参照設定から FSharp.Core 4.3.0.0 を外すと、デフォルトの FSharp.Core として 4.0.0.0 が選択されるのでしょうか。
実行時に FSharp.Core のバージョンを確認すると 4.3.0.0
ところが、
printfn "%A" <| System.Reflection.Assembly.GetAssembly( typeof<list<int>> ).FullName
というコードで実行時に FSharp.Core のバージョンを確認すると
"FSharp.Core, Version=4.3.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a"
と表示されます。実行時にロードされているのは 4.3.0.0 のようです。
2013-05-22 追記
この原因は分かりました(たぶん)。
F# プロジェクト作成時に自動生成されていた App.config に次のように書かれていました。
<assemblyBinding xmlns="urn:schemas-microsoft-com:asm.v1">
<dependentAssembly>
<assemblyIdentity name="FSharp.Core" publicKeyToken="b03f5f7f11d50a3a" culture="neutral" />
<bindingRedirect oldVersion="2.0.0.0" newVersion="4.3.0.0" />
<bindingRedirect oldVersion="2.3.5.0" newVersion="4.3.0.0" />
<bindingRedirect oldVersion="4.0.0.0" newVersion="4.3.0.0" />
</dependentAssembly>
</assemblyBinding>つまり 4.0.0.0 を参照していても実行時に 4.3.0.0 にリダイレクトされていた、ってことでしょうか。この bindingRedirect をコメントアウトしたところ、4.0.0.0 がロードされるようになりました。
(Twitter で @igeta さんよりヒントを頂きました。ありがとうございました。)
参照先を FSharp.Core 4.3.0.0 に戻せない
再び参照設定で FSharp.Core を 4.3.0.0 に戻したところ、何故か Seq.where のエラーが直りません。4.3.0.0 を参照すれば SeqModule に Where が定義されているはずなのに何故・・・。
不審に思って再度参照設定を確認すると、あーら不思議、FSharp.Core のバージョンが 4.0.0.0 に勝手に書き換わっています。何度やってみても結果は同じでした。
どうやら一旦 FSharp.Core の参照を外してしまうと、Visual Studio 上では二度と FSharp.Core 4.3.0.0 を参照させることが出来なくなってしまうようです。ちなみに fsproj ファイルをテキストエディタで開いて書き換えればOKでした。
MissingMethodException ?
上記の挙動は謎ですが、とにかく今の目的は FSharp.Core 4.0.0.0 に切り替えることですから、謎は放置して 4.0.0.0 に切り替える作業を進めました。
ところが、何故か実行時に MissingMethodException が出るようになりました。訳がわかりません。オブジェクトブラウザで確認すればそのメソッドが存在していることは確認できますし、そもそも静的型付け言語を使っているのに MissingMethodException が出るなんて変です。
これは再現手順がきちんと整理できていないので FSharp.Core が原因だという確証を掴んだわけではなく、私の不手際の可能性も残っていますが・・・。
2013-05-22 追記
憶測に過ぎないのですが、もしかして上に追記した App.config の bindingRedirect の件と関係があるかも、などと思い始めました。
この例外は C# のプロジェクトから F# のアセンブリを呼び出した時に発生していました。そして C# のプロジェクトに自動で追加される app.config には FSharp.Core をリダイレクトするような設定は書かれていません。C# 側の app.confing にも bindingRedirect を記述すればもしかして直るのかな・・・などと思いました。(今もろもろ元に戻してしまったので現象がすぐには再現できず、これで直るのかどうか確認できてないのですが)
→ 直りました!!
結局どうしたらいいのん?
今のところお客様に .NET 4.5 をインストールして頂いて作業は進められているので、このまま行くしかないのかなあ。なんか気持ち悪いなあ。
どうしてこうなるのか、メカニズムがハッキリするだけでも心が落ち着くんだけど。
どうも自分はググるのが下手なのか、検索しても本件の答えを見つけられず・・・。
どなたかご存知のかたは教えて下さい m(_ _)m
2013-05-22 さらに追記(結論?)
@yukitos さんのタレコミで似たような問題でハマっている Stack Overflow の記事を知りました。
f# 3.0 - How to generate C#-friendly, .Net 4.0 compatible types using F# 3.0 type providers - Stack Overflow
やはり .NET 4.0 しかインストールされていない環境でビルドにトラブルが生じている様子です。この記事の中で Brian さんという方が
FSharp.Core 4.3.0.0 does not depend on anything in .Net 4.5, it only depends on .Net 4.0.
と書いていますので、.NET 4.0 の環境でも FSharp.Core 4.3.0.0 は問題なく利用(実行)できるようです。Brian 氏はプロフィールに "I’m a developer on the F# team at Microsoft." と書いてありますから、このコメントは信頼出来ます。
ただし開発環境には .NET 4.5 が入っていないとNGのようですので、開発環境にのみ .NET 4.5 を入れる必要があります。整理すると、結論は次のようになるかと思います。
- FSharp.Core 4.3.0.0 は .NET 4.0 のみの環境でも実行可能。実行環境には .NET 4.5 は必要ない。
- ただし VS2010 で FSharp.Core 4.3 を利用する場合は、その開発環境にのみ .NET 4.5 をインストールする必要がある(これが最もシンプルな解決策)
- 以上により、VS2012 では FSharp.Core 4.0.0.0 を使う必要はない。
(@yukitos さん、大変ありがとうございました)
ゲーム/映像的なものと工学的なものの違い
なんか似ているようで異なる技術。
ゲームで出来てるのにどうしてCADやCAEでは出来ないのか、などと言われることがあってみたり、自問自答してみたり。
ちょっと整理してm・・・いや、書き散らかしてみる。整理はしてない。
IK (Inverse Kinematics; 逆運動学)
ゲーム/CG系でいうIKと、ロボット工学系でいうIKは、似ているようで結構違いがありそう。
各関節の角度(足の付根、膝、足首など)からつま先の位置を求めるのがFK(Forward Kinematics)、逆につま先の位置から各関節の角度を求めるのがIK(Inverse Kinematics)。
MMD(MikuMikuDance)のモーションデータ(VMDファイル)を再生するプログラムを組んだことがある。キャラクタの3Dデータ(PMDファイル)をモーションデータに沿ってアニメーションさせるプログラムだ。
MMDでは下半身のモーションはIKを使って定義されている。どういうことかというと、与えられた腰の位置やつま先の位置を元に、適切な膝の角度を自動で計算しなくてはならないということだ。
参考:http://d.hatena.ne.jp/edvakf/20111102/1320268602
上記ページを見ればわかるけど、アルゴリズムは割と単純で「なんと、こんな程度のアルゴリズムでそれっぽく動くのかー!」とちょっとした感動を覚えた。
でも産業用ロボットのIKはそんなに簡単には行かなそうだ。こちらは作った経験ないので単なる想像だけど。
ロボットにおけるIKは、指定された手先の位置と向きを厳密に守らなくてはならない。ロボットは手先で仕事をする。モノを掴んだり、塗装をしたり。だから指定された位置や向きを厳密に守らなくては仕事ができない。
一方MMDで使われているIKは「それっぽく見える」だけで厳密にIKボーンの位置と向きをトレースしないので、ロボットには適用できないはず。
それに加えてロボットでは
- 様々な機種(関節数が違ったり関節の自由度が違ったり)に対応しないといけない。
- 関節の曲がる角度に制限がある。
- 手先の位置が合っていても、肘関節の位置が他の物体に接触してはいけない。
などの厄介な問題がありそう。
そう考えるとロボットのほうが難しそうだが、一方でゲームほどリアルタイム性は求められない。
物理演算
最近ゲームはいとも簡単にヌルヌルと物理演算が動いていて驚かされる。
以前 BulletSharp という物理エンジン(Bullet Physics の .NET ラッパー)で遊んでみたことがある。カオスな動きをするはずの「二重振り子」を BulletSharp でシミュレーションしてみたのだ。
結果は、全然カオスな動きにならなかった。単純に揺れるだけで、あっというまに揺れが収束してしまう。
つまり、Bullet Physics は正確に物理をシミュレーションしているわけではないということが分かる。リアルタイム性を確保するために演算ロジックには何らかの「ごまかし」が入っているのだと思う。ゲームなどで「それっぽく」見せるには十分だが、物理シミュレーションとしては使えない。
衝突判定
ゲームの衝突判定は、直方体や球やカプセル(薬の)みたいな形で形状を近似して行なっているようだ。詳しく知らないんだけど、MMDとかUnityとかを見たらそんな感じだった。
一方で工学系では現実世界をシミュレーションする必要があるので、ポリゴン等で構成された複雑な形状同士をそのまま正確に衝突判定しなくてはならない。場合によっては「物体同士の距離が 5mm 以下まで近づいたら警告」みたいな距離判定も必要になる。
というわけで衝突判定はゲーム/映像系と工学系で全然違う。
CADとCG
ここが一番詳しいだけに一番書きにくい。
うまく端折って簡単に紹介できない。
というわけでバッサリ割愛(笑)。まあ、内容は上記の延長で推して知るべし。
あと、あれだ。ゲームや映像系で演算を間違えても何も壊れないし誰も死なないんだけど、工学系では現実世界に被害が及ぶからなー。
リーマンのゼータ関数を描画してみた
数々の数学者の人生を狂わせたリーマン予想というものがある、ということは以前から知識として知ってはいたのですが、とあるキッカケでなんとなくWikipediaで調べてみました。
ゼータ関数を次のように定義する。
リーマン予想 - Wikipedia
1859年にリーマンは自身の論文の中で、複素数全体 (s ≠ 1) へゼータ関数を拡張した場合、
ζ(s) の自明でない零点 s は、全て実部が 1/2 の直線上に存在する。
と予想した。
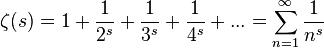
あーそういえば数学ガールでバーゼル問題は読んだなあと思いつつ、難しいことはサッパリ分からんが正月休みのヒマを埋めるべくとりあえずゼータ関数を可視化してみたら面白いかもしれんと、プログラミングの書き初めを始めたわけであります。
まずゼータ関数に出てくる数列を次のように定義します。(あ、C#ね)
static IEnumerable<Complex> ZetaSequence( Complex z ) { int n = 1; while ( true ) yield return 1.0 / Complex.Pow( n++, z ); }
.NET Framework 4.0 から Complex 型が導入されたので大変便利ですなー。
次にこの数列の和を計算してゼータ関数が定義されます。
static Complex ZetaFunc( Complex z ) { const int N = 1000; return ZetaSequence( z ).Take( N ).Aggregate( Complex.Zero, ( acc, item ) => acc.Magnitude < 10.0 ? acc + item : acc ); }
ここでは数列の1000項まで計算することにしました。あと、無限大に発散されても困るので絶対値10未満に抑えました。
ここからゴニョゴニョと色々やって、OpenGLで描画したものがこちら。

おお!確かに X = 1/2 の直線上にツノのような形のゼロ点があるではないか!
ちなみに、Z軸はゼータ関数の絶対値、色は偏角を色相に割り当てたもの。
裏から見るとこんな感じ。

もっとY軸方向に大きく描画してみたものがこちら。

う、美しい・・・。
なんといいますか、数々の数学者たちの挑戦を跳ね除けたエピソードを知った上でこの形を眺めると、なんだか妖しい美しさがあるように感じられてしまうものですね。
僕は人生をこれ以上狂わせたくないので、リーマン予想に深入りするのは辞めておきます。深入りするだけの能力が無いだけですが。みなさんも気をつけましょう。
")
- 作者: 結城浩
- 出版社/メーカー: ソフトバンククリエイティブ
- 発売日: 2007/06/27
- メディア: 単行本
- 購入: 56人 クリック: 1,029回
- この商品を含むブログ (972件) を見る