Weak Event パターン
Weak Event パターンをもっと簡単に実装する方法はないのかな、と思って色々と試行錯誤してみました。あんまり自信はありませんが、とりあえずこれでいいのかな、というものが出来たので晒してみます。変なとこあったら教えて下さい m(_ _)m
まず Weak Event でない場合にどんな問題が起こるか、簡単なプログラムで再現させてみます。
open System type EventSource () = let event = Event<EventHandler, EventArgs> () [<CLIEvent>] member __.Event = event.Publish member __.Fire () = event.Trigger (null, EventArgs.Empty) type EventListener (source : EventSource, id) = let subscribe = source.Event |> Observable.subscribe (fun _ -> printf "%d, " id) override __.Finalize () = printfn "finalized %d" id; subscribe.Dispose () let source = EventSource () let mutable listener = Unchecked.defaultof<EventListener> for id = 1 to 10 do listener <- EventListener (source, id) source.Fire () GC.Collect() printfn ""
この出力結果は次のようになります。
1, 1, 2, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, finalized 10 finalized 1 finalized 9 finalized 8 finalized 7 finalized 6 finalized 5 finalized 4 finalized 3 finalized 2 続行するには何かキーを押してください . . .
listener 変数を書き換えているにも関わらず、イベントハンドラがイベントソースに強参照で登録されているために listener が全く Finalize されていないことが見て取れます。
そこで EventListener を次のように書き換えます。
type EventListener (source : EventSource, id) = let callback = Action<EventArgs> (fun _ -> printf "%d, " id) // コールバックは強参照で保持 let subscribe = let callbackRef = WeakReference<_> callback // イベントに登録するのは弱参照 source.Event |> Observable.subscribe (fun arg -> match callbackRef.TryGetTarget () with true, callback -> callback.Invoke arg | _ -> ()) override __.Finalize () = printfn "finalized %d" id; subscribe.Dispose () member private __.__ = callback // これがないと callback フィールドが作られない!
これで再び実行すると次のような結果になりました。
1, 1, 2, 2, 3, 3, 4, finalized 1 4, 5, finalized 5, 2 finalized 3 finalized 4 6, finalized 5 6, 7, 7, 8, finalized 6 finalized 7 8, 9, 9, 10, finalized 8 finalized 9 finalized 10 続行するには何かキーを押してください . . .
ループの途中で EventListener が Finalize されていることが分かります。
処理の進捗通知について
私は計算時間がかかる処理を作ることがちょくちょくあります。といっても何時間も計算機をぶん回すような計算はあまりなくて、数秒から数十秒程度の計算が殆ど、長くても数分でしょうか。この程度の計算時間でも計算処理の進捗状況が可視化されないとユーザーはイライラを感じますから、プログレスバーで大まかな進捗状況を可視化する必要が出てきます。
しかし当然ながら計算アルゴリズムを ProgressBar のような GUI 部品に依存させる設計は出来ませんから、処理の進捗を通知する部分をGUIから切り離す必要があります。今までは計算処理APIの引数にコールバック(のようなもの)を渡して進捗の通知を行ったりしていました。これを F# ならどう書くのがスマートなのか、思案しています。
重要なポイントとして、ある計算処理の中で別の計算処理を呼び出すことが当然ながらあります。とある計算処理Aは、それを単独で使用されることもあれば、別の計算処理Bの中で呼ばれることもあるということです。Aを単独で使用する場合はAの呼び出し終了時に進捗は100%で良いですが、処理Bから処理Aを呼び出している場合にはAだけで進捗を100%とするわけにはいきません。処理Bにおいて処理Aが占める割合を重み付けして進捗を通知する必要があります。こういう通知処理をスマートに書く方法が欲しいと思っています。
最初は「コンピュテーション式ってやつを勉強して使ってみたい」と思って考えていました。そういう意味では目的と手段が逆になっていたかもしれません。今はだんだん、コンピュテーション式にこだわらなくてもいいかな、という気持ちになってきています。(まだ自分の中で結論が出たわけではありません。とりあえず現状では、ということです。)
問題設定
サンプルとして計算時間がかかる処理を3つ用意します。listener というのは進捗の通知を受け取るコールバックで、float -> unit 型です。
let heavyFuncA listener = printfn "heavyFuncA started.." for i in 1..10 do Thread.Sleep 10; listener 0.1 100 let heavyFuncB a listener = printfn "heavyFuncB started.." for i in 1..10 do Thread.Sleep 10; listener 0.1 a / 2 let heavyFuncC b listener = printfn "heavyFuncC started.." for i in 1..10 do Thread.Sleep 10; listener 0.1 b / 5
これら3つの関数を順番に呼び出す計算処理をスマートに書く方法を検討していきます。
ナイーブな書き方
let heavyFuncNaive listener = let a = heavyFuncA (fun step -> listener (0.2 * step)) let b = heavyFuncB a (fun step -> listener (0.5 * step)) let c = heavyFuncC b (fun step -> listener (0.3 * step)) c
これでもいいのかもしれませんが、ちょっとダサい感じがします。
(0.2, 0.5, 0.3 といった数値が各関数の重み付けです。合計が 1.0 となるように重みを配分する必要があります。)
関数の合成を使う
let heavyFuncByComposition listener = let a = heavyFuncA ((*) 0.2 >> listener) let b = heavyFuncB a ((*) 0.5 >> listener) let c = heavyFuncC b ((*) 0.3 >> listener) c
だいぶいい感じになりました。こうやって合成して書けることにしばらく気づきませんでした。まだ修行が足りませんね…。もうこれでいいんじゃないの、という気分にもなってきますが…。
演算子を定義してみる
こういう演算子を定義してみます。
let ( *>>) weight listener = (*) weight >> listener
するとこう書けます。
let heavyFuncByOperator listener = let a = heavyFuncA (0.2 *>> listener) let b = heavyFuncB a (0.5 *>> listener) let c = heavyFuncC b (0.3 *>> listener) c
さっきよりちょっとだけ短くなりました。うーん、これだけのために演算子を定義するのは evil かもしれません…。どうなんでしょう?
weightListener 関数
こういう関数を定義します。前述の *>> 演算子を利用しています。というか、*>> 演算子と引数の順序が逆になっただけです。
let weightListener listener weight = weight *>> listener
するとこう書けます。
let heavyFuncByWeightListener listener = let w = weightListener listener let a = w 0.2 |> heavyFuncA let b = w 0.5 |> heavyFuncB a let c = w 0.3 |> heavyFuncC b c
w の定義行が一行増えますが、なかなかよい感じです。
コンピュテーション式
分かりやすさのため、次のような関数型に別名を付けておきます。
type ProgressListener = float -> unit type Progressive<'a> = ProgressListener -> 'a
次のようなビルダーを定義してみました。
type ProgressiveBuilder (listener : ProgressListener) = member this.Bind((weight, calculation : Progressive<'a>), remaining : 'a -> Progressive<'b>) : Progressive<'b> = fun listener -> calculation (weight *>> listener) |> remaining <| listener member this.Return x : Progressive<_> = fun _ -> x member this.Zero () : Progressive<_> = fun _ -> Unchecked.defaultof<_> member this.Delay x = x member this.Run f = f() <| listener member this.Combine (_, f) = f () let progressive listener = ProgressiveBuilder listener
すると次のように書けます。
let heavyFuncByCexpr listener = progressive listener { let! a = 0.2, heavyFuncA let! b = 0.5, heavyFuncB a let! c = 0.3, heavyFuncC b return c }
とてもシンプルで読みやすいですね!
これは @bleis さんからアドバイスを頂いたり、@nagat01 さんが作成したコード https://gist.github.com/nagat01/a5b5977286f56a353b77 を参考にしつつ、自分の好みで少し書き換えたものです。@bleis さん、@nagat01 さん、ありがとうございました。
しかし現状、while や for が使えません。これらを使えるようにするにはビルダーに While() や For() を定義する必要があるようですが、それは私の能力を超えているようです。@bleis さんの記事 詳説コンピュテーション式 - ぐるぐる~ とだいぶ睨めっこしたのですが、、、撃沈しました><

STAPと美味しんぼと信念の倫理
かの有名なトム・デマルコの著作「熊とワルツを」を本棚から引っ張り出してきました。

- 作者: トム・デマルコ,ティモシー・リスター,伊豆原弓
- 出版社/メーカー: 日経BP社
- 発売日: 2003/12/23
- メディア: 単行本
- 購入: 7人 クリック: 110回
- この商品を含むブログ (150件) を見る
改めて非常に示唆的な内容だと感じたので、簡単に紹介してみたいと思います。なお、本書はソフトウェア開発プロジェクトのリスクマネジメントについて書かれた本ですが、ここで紹介する「信念の倫理」という論文はソフトウェア開発ともリスクマネジメントとも直接関係する内容ではありません。ソフトウェア開発と縁のない方でも読める内容です。
「信念の倫理」の原題は "The Ethics of Belief" です。この「信念」の意味が一般的な日本語の意味とややニュアンスが異なっているかもしれません。「信念を貫き通す」みたいなニュアンスではなく、単に believe の名詞形として「信じること」「信じていること」と解釈するほうがしっくり来ると思います。
さて、個人が何を真実として信じるのかは各人の勝手であり自由である、というのは割と普通な考え方だと思います。もちろん、その信念が具体的な行為として発露した際にはその行為の倫理性が問われます。しかし心の内にあるかぎりは何を信念としようが倫理的な問題は問われない、と考えるのが普通ではないでしょうか。(宗教の信徒の場合は神を冒涜するような信念を抱くこと自体が罪という倫理観があるかもしれません。)
ところが「信念の倫理」では、何らかの信念を抱いた時点でそれが倫理性が問われる対象となり得る、と主張しています。誤った信念を持つこと自体が倫理に反するということです。
具体例として「信念の倫理」では次のような架空のエピソードが書かれています。ある船主が移民船を航海させようとしていました。船は老朽化しており作りも良くなかったのですが、船主は移民たちの安全を心から「信じて」送り出します。かくして老朽化のために船は沈没してしまいます。確かにこの船主に悪意はなかったが、それはこの船主の罪をなんら軽くするものではありません。この船主は船旅の安全を信ずるに値するだけの調査を怠っていたのです。つまりそのような信念を抱く権利がこの船主にはなかったのです。
では少し話を変えて、老朽化した船は航海に何とか耐えて事故は起こらなかったとします。その場合でもこの船主の罪は軽くならないと論文は主張します。船主が船の安全を確認する誠意ある調査を怠ったことに変わりはないのだから、この船主が船の安全を信じる権利はなかったです。つまり、事故が起こったか起こらなかったかという結果とは関係なく、誤ったプロセスで信念を抱いたこと自体が罪だというのです。
この論文では、倫理の追求先を責任ある立場の人物だけに限っていません。上記のエピソードでは船主が重要な責任を負う立場であることが明白ですが、そのような立場にない無名の人物でも、どんなに些細な信念でも、倫理の審判の対象となると言っています。信念というのは人間のエネルギーを凝縮し調和させる人類全体にとって神聖な財産であり、誤ったプロセスで信念を持つことはその財産の神聖性を毀損する、といった内容まで書かれています。厳しいですね…。
この論文が発表された時は、会場は拍手と怒号が入り乱れて大荒れだったそうです。確かに物議を醸す内容ですね。今風に言えば「炎上した」という状況だったのかも、と想像します。(なお、「罪」とか「権利」といった言葉が出てきますが、あくまで「倫理」の話なので法律上の罪とは分けて考えるべきだと私は解釈しています。法律上は内心の自由は保証されなくてななりません。)
昨今の騒動には「その信念を抱くに足るだけの誠実な調査があったのだろうか」との疑念を感じると同時に、自分自身が抱いている信念も問いなおす必要があるかもしれませんね。
波の干渉を可視化してみた
現在、四苦八苦しながらファインマン物理学2巻を読んでいるのであります。

- 作者: ファインマン,富山小太郎
- 出版社/メーカー: 岩波書店
- 発売日: 1986/02/07
- メディア: 単行本
- 購入: 4人 クリック: 14回
- この商品を含むブログ (12件) を見る
今のところ1/3くらいは読んだかな…?ファイマン先生が舌鋒鋭く光の屈折の本質に迫っていく辺りに感動を覚えつつも、まあ、消化不良ですね。それはともかく、波の干渉の様子をOpenGLで可視化できたら面白いかもしれんなどと思いましてプログラムを書いてみました。本当は屈折の原理に感動したので屈折をシミュレートするプログラムが作ってみたかったのですが、ちょっと考えただけでも難しそうだったのでそれはあっさり諦めました(^^;
まず波源を定義します。
type WaveSource = {
Position : Point2d
Amplitude : double
Lambda : double
}Point2d の定義は書いてありませんが、名前から想像がつく通り2次元の点座標です。2次元平面上の点と振幅(Amplitude)、波長(Lambda)によって波源が定義されます。
次に、複数の波源から構成される「場」を定義します。
type WaveField = {
WaveSources : WaveSource list
FieldSize : Size2i
FieldOrigin : Point2i
LengthPerPixel : double
}Size2i は整数値による2次元のサイズ(つまり幅と高さ)、Point2i は整数値による2次元座標です。離散化された2次元のグリッド上に波を発生させてそれを可視化しようというわけです。ですのでグリッドのサイズやら解像度やら原点位置やらを表すフィールドが並んでいます。
次に示すのは一つの波源が発生させる波を表す関数です。
let private evalWaveSource source (p : Point2d) = let r = (p - source.Position).Length let k = 2.0 * Math.PI / source.Lambda source.Amplitude * (if r < 1.0e-6 then k else sin (k * r) / r)
source は WaveSource 型の波源です。この関数は波源 source が位置 p に起こす波の振幅を返します。特異点のゼロ割を回避するコードを除けば、三角関数によるシンプルな波であることが読み取れるでしょう。
単純な一つだけの波源
まずは単純に、波源を一つだけ置いて可視化してみます。

場は次のように定義しました。
{ WaveSources = [{ Position = Point2d (0.0, 0.0); Amplitude = 400.0; Lambda = 20.0 }]
FieldSize = Size2i( 512, 512 )
FieldOrigin = Point2i( 256, 256 )
LengthPerPixel = 1.0 }描画はOpenGLで行っていますが、独自ライブラリを使っていますしコードもやや煩雑なので説明は省きます。
※ 振幅やら波長やらは見た目が良い感じになるように調整しただけですので特に意味がある数値ではありません。
指向性のある波源
今度はX軸上に複数の波源を並べてみたものです。波長よりも短い間隔で波源が並べられていることがミソです。こうするとY軸方向に指向性のある波が生成されるとのことですが…。
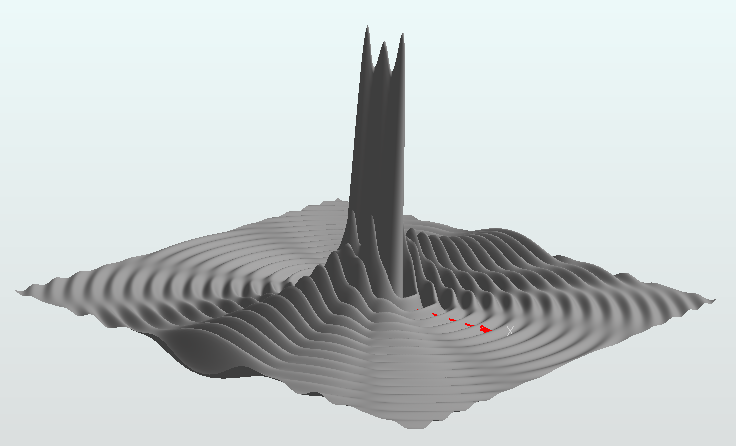
X方向から見た図(つまりYZ面)。

Y方向から見た図(つまりXZ面)。

おおー、確かにY軸方向に指向性が現れています。Y軸上では全ての波源の位相が一致するので互いに強め合って波が遠くまで伝送されますが、それ以外の方向へは位相がズレるため互いに打ち消し合ってしまい、波は伝送されません。
場は次のように定義しました。X軸上に 5.0 間隔で波源が13個並んでいます。
let waveSource x =
{ Position = Point2d (x, 0.0); Amplitude = 400.0; Lambda = 20.0 }
let sources =
[0.0; 5.0; -5.0; 10.0; -10.0; 15.0; -15.0; 20.0; -20.0; 25.0; -25.0; 30.0; -30.0]
|> List.map waveSource
{ WaveSources = sources
FieldSize = Size2i( 512, 512 )
FieldOrigin = Point2i( 256, 256 )
LengthPerPixel = 1.0 }
干渉縞を作る波源
最後は、有名な干渉縞を作る場のシミュレーションです。波源の塊を少し離れた位置に2つ配置しています。
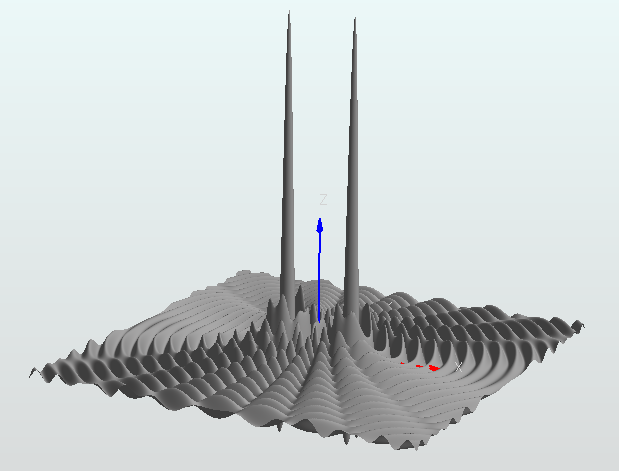
学校の授業でレーザー光をスリットに当ててスクリーンに干渉縞を投影した実験が懐かしいです。場は次のように定義しました。2つの波源の塊が 80.0 の間隔を空けて並んでいます。これが二重スリットを通り抜けた2つの光源をシミュレートしています。
let waveSource x =
{ Position = Point2d (x, 0.0); Amplitude = 400.0; Lambda = 20.0 }
let sources =
[ waveSource 40.0; waveSource -40.0
waveSource 43.0; waveSource -43.0
waveSource 46.0; waveSource -46.0
waveSource 49.0; waveSource -49.0 ]
{ WaveSources = sources
FieldSize = Size2i( 512, 512 )
FieldOrigin = Point2i( 256, 256 )
LengthPerPixel = 1.0 }以上、単に複数の波を重ねあわせただけの単純な実験ですが、ちょっと楽しいですね。
初めての WPF 事始め
この文章は先日中途で入社されたSさんに向けて書いています。SさんはC++とJavaの経験はあるが、C#やWPFの経験はないそうです。
私は一般向けに解説記事が書けるほどWPFに詳しいわけでは全くありませんが、そうは言ってもSさんには業務が回せる程度の知識を伝えなければならないわけで、ならばブログとして説明記事を公開してしまってあわよくば誤りを訂正して頂いたり補足を頂ければラッキー、などと思ったのが書き始めた経緯です。といっても、ほんの導入部までしか書けませんでした。「口頭で伝えるほうが手っ取り早いんじゃないか」とか思い始めちゃうとなかなかモチベーションが続かないですね(^^; とりあえず今後の学習の取っ掛かりになればいいなあという程度の浅~い内容ということで、簡単な Binding までを書きました。
WPFのメリット
WPFのメリットは次の2点です。
- ビューとロジックを分離した綺麗な設計ができる(MVVMパターン)
- ビューのデザインの自由度が高い
ここでは前者の特長を伝えたいと思います。理由は2つあって、まずウチの業務では凝ったGUIデザインを追求することよりもメンテナンス性の高い綺麗な設計を実現するほうが重要度が高いこと、次にGUIデザインを追求するにしてもまず土台となる設計がきちんとできることが前提であると思うことです。
XAMLとは
Visual Studio で WPF アプリケーションを作成すると、次のようなXMLが自動生成されます。これがXAML(eXtensible Application Markup Language)というヤツです。XAMLと書いて「ザムル」と発音するようです。
<Window x:Class="WpfApplication1.MainWindow" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" Title="MainWindow" Height="350" Width="525"> <Grid> </Grid> </Window>
このXAMLを使ってGUIをデザインするのですが、ここではGUIのデザインで使用するXAMLの要素についていちいち説明しません。それはググるなり本を読むなり既存コードを読むなりすれば分かることだと思います。それよりも、XAMLとはなんぞや、という大枠をザックリと掴んでおきましょう。
XAMLというのはGUIデザイン専用言語ではありません。他の目的にも使用しうるものです。それを理解するために、まず次のようなクラスを定義してみます。
public class Piyo { public int Foo { get; set; } } public class Hoge { public Piyo Piyo { get; set; } }
そして次のようなXAMLファイル(Hoge.xaml とします)を作成します。
<Hoge xmlns="clr-namespace:WpfApplication1"> <Hoge.Piyo> <Piyo Foo="123"/> </Hoge.Piyo> </Hoge>
そうしますと、次のように Hoge のインスタンスを XAML から生成することが出来るのです。
// hoge.Piyo.Foo は 123 に初期化されている var hoge = (Hoge)Application.LoadComponent( new Uri( "/WpfApplication1;component/Hoge.xaml", UriKind.Relative ) );
つまり、XAMLというのはオブジェクトのプロパティを設定する初期化処理をXML形式に則って宣言的に書けるもの、ということになります。決してGUIデザインに特化した言語ではないということが分かるかと思います。
DataContextプロパティ
WPFのライブラリは巨大です。膨大なクラス、膨大なメソッド、膨大なプロパティ。その中でも最初に覚えて欲しいのがこの DataContext プロパティです。大げさな言い方ですが、膨大なプロパティの中でこの DataContext プロパティは燦然とひときわ明るく輝いているのです。
さあ、次のようなクラスを用意して MainWindow.xaml の DataContext プロパティに設定してみましょう。
class MainWindowModel {...}
<Window x:Class="WpfApplication1.MainWindow" ... xmlns:a="clr-namespace:WpfApplication1"> <Window.DataContext> <a:MainWindowModel/> </Window.DataConext> ... </Window>
図で表すと次のようになります。

これがWPFプログラミングの出発点です。ビューのデザイン(見た目)は MainWindow (XAML) で、ビューの状態管理は MainWindowModel で、と役割分担するのがWPFプログラミングの基本となります。
Data Binding
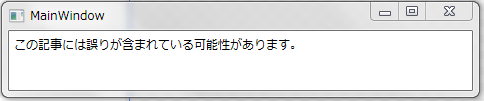
Binding という機能を使うと、DataContext(ここでは MainWindowModel)に定義されているプロパティをビューに「バインド」することが出来ます。まずは単純な例として MainWindowModel に Message プロパティを定義し、これを MainWindow 上に Label として表示してみましょう。
class MainWindowModel { public string Message { get { return "この記事には誤りが含まれている可能性があります。"; } }
<Window ...> <Window.DataContext> <a:MainWindowModel/> </Window.DataConext> <StackPanel> <Label Content="{Binding Path=Message}"/> </StackPanel> </Window>
こうなります。
この例ははじめの一歩としては悪くありませんが、ラベル文字列は固定で何の変化もありませんから面白みに欠けますね。ではユーザーに「同意」を促すチェックボックスを追加してみましょう。
class MainWindowModel { ... bool isAgreed; public bool IsAgreed { get { return isAgreed; } set { isAgreed = value; } // ← ここに break point を仕掛けてみよう! } }
<Window ...> ... <Label Content="{Binding Path=Message}"/> <CheckBox IsChecked="{Binding Path=IsAgreed}">同意します</CheckBox> ... </Window>
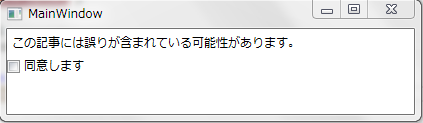
IsAgreed プロパティにブレークポイントを仕掛けてチェックボックスをON/OFFしてみてください。チェック状態の変化が MainWindowModel に伝達されることが分かるはずです。これが Binding の威力です。この機能のお陰で、ビューの状態管理を簡単に別のクラス(ここでは MainWindowModel)に分離することができるようになるのです。
なお、Binding 出来るのは「依存関係プロパティ(Dependency Property)」というちょっと特殊なプロパティだけです。しかしWPFコントロールのプロパティはほとんど全て Dependency Property として定義されていますので最初はあまり意識する必要はないと思います。
INotifyPropertyChanged インターフェイス
実は今までの MainWindowModel には問題が残っていて、これを解決するのが INotifyPropertyChanged インターフェイスです。
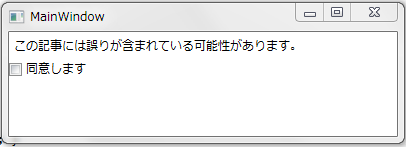
まずは問題点をあぶり出すサンプルを作っていきましょう。画面に「次へ」ボタンを追加し、「同意します」にチェックが入っている場合のみ「次へ」ボタンが表示されるようにしたいと思います。
「次へ」ボタンの可視性(Visibility)は次のようなプロパティで定義できるでしょう。
class MainWindowModel { ... public Visibility NextButtonVisibility { get { return this.IsAgreed ? Visibility.Visible : Visibility.Collapsed; } } }
XAMLに「次へ」ボタンを追加し、その可視性を NextButtonVisibility プロパティにバインドします。
... <Label Content="{Binding Path=Message}"/> <CheckBox IsChecked="{Binding Path=IsAgreed}">同意します</CheckBox> <Button Visibility="{Binding Path=NextButtonVisibility }">次へ</Button> ...
さあ起動してみましょう。残念!チェックボックスをONにしてもボタンは表示されません。
この例ですと IsAgreed プロパティの値が変化すると同時に NextButtonVisibility プロパティも連動して変化するわけですが、その変化をビュー側(つまり MainWindow)が知る手段がありません。ですので NextButtonVisibility の値が変わっていることに MainWindow が気づかないのです。この問題を解消するためには、MainWindow にプロパティの変化を通知してあげる必要があります。そのためのインターフェイスが INotifyPropertyChanged なのです。次の図のように MainWindowModel がこのインターフェイスを実装する必要があるのです。

INotifyPropetyChanged インターフェイスの定義は下記のとおりです。
namespace System.ComponentModel { // 概要: // プロパティ値が変更されたことをクライアントに通知します。 public interface INotifyPropertyChanged { // 概要: // プロパティ値が変更するときに発生します。 event PropertyChangedEventHandler PropertyChanged; }
これを MainWindowModel に実装しましょう。
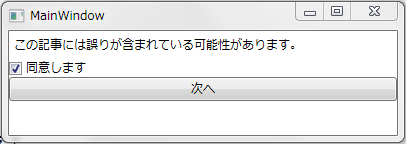
class MainWindowModel : INotifyPropertyChanged { ... public event PropertyChangedEventHandler PropertyChanged; void RasePropertyChanged( params string[] propertyNames ) { if ( this.PropertyChanged != null ) { foreach ( string name in propertyNames ) this.PropertyChanged( this, new PropertyChangedEventArgs( name ) ); } } public bool IsAgreed { get { return isAgreed; } set { isAgreed = value; // ↓↓↓変更通知↓↓↓ this.RasePropertyChanged( "IsAgreed", "NextButtonVisibility" ); } } }
IsAgreed プロパティの set 関数でプロパティの変更通知を行っているのがポイントです。isAgreed への代入により IsAgreed プロパティと NextButtonVisibility プロパティの2つが変化しうるので、その2つのプロパティの変更通知を行っています。
この状態で起動してみると、チェックボックスのON/OFFにボタンの表示/非表示が連動することが確認できるはずです。
C++プログラマ向けC#ひとめぐり
この文章は先日中途で入社されたSさんに向けて書いています。SさんはC++とJavaの経験はあるが、C#の経験はないそうです。
という事情でして、C++やJavaと対比しながらC#を説明すれば手っ取り早くC#を覚えて頂けるかな、などと思うわけです。しかしながら私自身C++は最近書いてないし、Javaに至っては10年以上前に少し触ったことがあるだけ、という状態。とりあえずJavaとの比較は諦めます。C++についても全くもって正確な記事が書ける自信がないことをお断りするとともに、間違ってたらぜひツッコミよろしくおねがいします><
(あ、あと C++11 は分からないので、C++11 以前の C++ を前提に書いています。SさんもC++11に詳しいわけでは無さそうですし…)
class と struct
C++ では class と sturct に本質的な違いがなく、単にメンバがデフォルトで public か private かの違いしかありません。しかし C# では class と struct は全く違うものです。
class Hoge { ... }; Hoge hoge; // スタックに積まれる Hoge* ptr = new Hoge(); // ヒープに生成される Hoge hoge2 = hoge; // 値がコピーされる(コピーコンストラクタ/コピー演算子) Hoge* ptr2 = ptr; // ポインタのコピー
class Hoge { ... } struct Piyo { ... } Hoge hoge = new Hoge(); // class はヒープに生成される Piyo piyo = new Piyo(); // struct はスタックに積まれる Hoge hoge2 = hoge; // 参照のコピー Piyo piyo2 = piyo; // 値のコピー
C++とC#で同じキーワードを微妙に違う意味で使っているので混乱を誘いますね(^^;
C# では new と書いてあっても struct ならスタックに積まれます。
const と readonly
優れたC++プログラマは丁寧に const を付けますね。C#にも const キーワードは存在しますが、C++とは少し意味が違います。また、一部は readonly というキーワードに置き換えられています。
class Hoge { const int A = 123; // 整数などの数値は定数を定義できます const string B = "Hello"; // 文字列も定数に出来ます readonly string C; // コンストラクタで初期化されたらそれ以降は読み取り専用となります public Hoge( string c ) { this.C = c; } }
- C++ の const は「読み取り専用」を意味しますが、C# の const は「定数」です。システム全体を通して変化しない値です。
- クラスのメンバ(フィールド)を読み取り専用にしたい時は、const の代わりに readonly を使います。
- C++ では関数の引数やメンバ関数に const 属性を付けられますが、C# ではそういったことは出来ません。
クラスのフィールドは可能な限り readonly にする習慣をつけると良いと思います。
継承について
struct は継承できません。
class は継承できますが、多重継承は出来ません。その代わりに(?)インターフェイスは複数実装できます。このへんは Java と同じです。ですのでダイヤモンド継承とかバーチャル継承みたいな闇(…おっと誰か来たようだ)は存在しません。
コレクション(コンテナ)
C++のSTLで提供されているコンテナに(無理矢理)C#の(というより.NET Frameworkの)コレクションを対応付けてみました。
| C++ | C# |
|---|---|
| 配列 | T[] |
| vector<T> | List<T> |
| list<T> | LinkedList<T> |
| set<T> | HashSet<T> |
| map<T,U> | Dictionary<T,U> |
- これらは System.Collections.Generic 名前空間に定義されています。
- System.Collections 直下にあるクラスは黒歴史なので使わないで下さい。
- C# の List と C++ の std::list を混同しないように注意して下さい。
- C++ の set/map は二分木によるものですが、C# の HashSet や Dictionary はハッシュテーブルによるものですので、正確にはこれらは異なるものです。そういう意味では対応づけるべきではないのかもしれませんが、用途としては似ている場面が多いと思いますので上のような表にしました。
- 正直なところ、C++STLの方が自由度が高く高機能かと思います。
IEnumerable インターフェイス
これはとても大事なインターフェイスで、いずれ覚えて欲しい LINQ という機能にも関連してきます。
C++のSTLコンテナでは、コンテナ要素にアクセスするための統一的な方法として iterator を提供しています。C#では(.NETでは)この IEnumerable インターフェイスがコレクション要素にアクセスするための統一的な機能として用意されています。
| C++ | C# |
|---|---|
| iterator で列挙 | IEnumerable で列挙 |
| 全てのコンテナは begin(), end() を提供 | 全てのコレクションは IEnumerable<T> を実装 |
ContainerType c;
for (ContainerType::iterator it = c.begin(); it != c.end(); ++it) {
...
}
CollectionType c; foreach (var item in c) { ... }
IDisposable インターフェイス
C++ ではスコープを抜けるときに必ず変数のデストラクタが呼ばれます。ですので、これを利用してデストラクタでリソースの解放処理を行うことがよくあります。例えばファイル操作などでは、スコープを抜けるときにデストラクタで確実にストリームを close() するといったパターンです。
{
std::ifstream fin("test.txt");
...
} // スコープを抜けるときに close される
しかし C# ではクラスのインスタンスはすべてヒープに確保されますし、メモリ等の解放処理はガベージコレクタが自動で行いますのでデストラクタのタイミングを制御することが出来ません。ですのでC++のようにデストラクタによってスコープ離脱時の解放処理を行うことはC#では出来ません。
その代わりとして、C#には using キーワードと IDisposable インターフェイスが用意されています。
using ( var reader = new System.IO.StreamReader( "test.txt" ) ) { ... } // スコープを抜けるときに Dispose() が呼ばれる
using の中に IDisposable インターフェイスを実装したオブジェクトを宣言すると、そのスコープを抜けるときに確実に Dispose() メソッドが呼び出されるようになります。
ちなみに、自作クラスに真面目に IDisposable インターフェイスを実装しようとすると割とややこしいことになります。「C# Dispose パターン」とか「C# Dispose Finalize パターン」とかでググると情報が出てくると思いますので、興味がありましたら調べてみてください。
yield return
だんだんC++には無い概念の説明に入っていきます。
yield return はちょっと分かりにくい概念で、私も最初は理解に苦労した記憶があります。この場で簡単に説明しただけでサクッと理解できるようなものではないと思いますので、いずれウェブなり書籍なりできちんと学習して頂ければと思います。ここではとりあえず
yield return を使うと IEnumerable<T> インターフェイスを真面目に実装しなくても簡単に IEnumerable<T> なオブジェクトが生成できる
ということだけ覚えて下さい。以下にFizzBuzz問題を例に取ったコード例を示します。
static IEnumerable<string> FizzBuzz() { for ( int i = 0; true; ++i ) { if ( i % 3 == 0 && i % 5 == 0 ) yield return "Fizz Buzz"; else if ( i % 3 == 0 ) yield return "Fizz"; else if ( i % 5 == 0 ) yield return "Buzz"; else yield return i.ToString(); } } foreach ( string s in FizzBuzz() ) Console.WriteLine( s );
この例では延々と無限に Fizz Buzz を出力し続けます。
どうです?とっても不思議な気がしませんか?
ヒントとしては、まず FizzBuzz() は「普通の」関数ではありません。関数に yield return が含まれていると、C# コンパイラが「普通とは違う扱い」をします。FizzBuzz() は関数のような顔をしていますが、C#コンパイラは内部で IEnumerable<T> を実装したクラスを生成しているのです。
ちなみに余談ですが、私は最初 yield の意味もしっくり来ず、これも理解の妨げになった気がします。英和辞典を引いてもしっくり来る意味が載っていないのです。英英辞典を調べてようやく腑に落ちました。
http://www.ldoceonline.com/dictionary/yield_1
- to produce a result, answer, or piece of information:
直訳すれば「結果とか答えとか情報とかを生み出すこと」でしょうか。
var と型推論
C++でもC++11からautoキーワードが導入されましたのでご存じかもしれません。
// 分かりきっている型を2回書く必要があり冗長 VeryLongLongNameClass a = new VeryLongLongNameClass(); // var キーワードを使って冗長な記述を排除できます // (型推論により型情報は失われておらず、b はVeryLongLongName型) var b = new VeryLongLongNameClass(); // これは型情報が失われているのでvarとは全く違います object c = new VeryLongLongNameClass();
var は人によって賛否が別れるところがあり、型名を省くと読みにくくなるという理由で使用を制限するところもあるようです。うちの会社ではそういった制限はしておらず、var は使えるところではどんどん使えばいいと思っています。
(とはいえ、さすがに int はタイプ数が変わりませんから int と書きますけど(^^;)
ラムダ式(とデリゲート)
C++ですと関数ポインタとか関数オブジェクト(ファンクタ)が比較的近い概念かなと思います。ここでは Array の Find() 関数を例に説明します。Find()は配列から最初に条件に合致する要素を返す関数で、C++の std::find_if() とよく似ているので分かりやすいでしょう。
// C# の Array.Find() public static T Array.Find<T>(T[] array, Predicate<T> match)
// C++ の std::find_if() template<class InputIterator, class UnaryPredicate> InputIterator find_if ( InputIterator first, InputIterator last, UnaryPredicate pred)
Array.Find() を使って int の配列から最初の偶数値を取り出すコードを書いてみます。
static bool IsEven( int i ) { return i % 2 == 0; } ... var array = new[] { 1, 3, 7, 6, 4, 2, 9 }; int a = Array.Find( array, IsEven ); // 関数を渡す int b = Array.Find( array, delegate( int i ) { return i % 2 == 0; } ); // デリゲートによる無名関数 int c = Array.Find( array, ( int i ) => i % 2 == 0 ); // ラムダ式 int d = Array.Find( array, i => i % 2 == 0 ); // ラムダ式(型推論により型を省略)
4通りの書き方を示しましたが、一番下が最も簡潔ですね。つまりこの書き方を推奨します。
delegate は使わないで下さい。delegate はラムダ式が C# 3.0 で導入される前の名残りだと思って差し支えないです。
LINQ
いよいよLINQですが、本題に入る前に一点野暮な注意をしておかねばなりません。"LINQ" でググると "LinQ" というアイドルグループがヒットしますが、全く関係ありませんので惑わされないように!
さて、LINQとは Language Integrated Query の略で「リンク」と発音します。LINQ には次の3種類があります。
これらのうち、ウチの業務で使用しているのは LINQ to Objects のみです。業種上あまりデータベースなどを扱うことが少ないため、LINQ to SQL などは利用する機会がなく私も使用経験がないので全く説明できません。ですので、ググると LINQ to SQL 等の説明も出てきますが、LINQ to Objects のみを学習して頂ければ十分ですのでご注意下さい。
何はともあれ、まずコード例を見てみましょう。見ても最初はわからないと思いますが、ザックリと雰囲気を見て頂ければ。
using System.Linq; IEnumerable<int> sequence = new[] { 1, 3, 7, 6, 4, 2, 9 }; // (A) メソッドチェイン形式 var q1 = sequence .Where( i => i % 2 == 0 ).OrderBy( i => i ).Select( i => i % 3 ); // (B) クエリ式 var q2 = from i in sequence where i % 2 == 0 orderby i select i % 3;
(A)(B)どちらも、「sequence から偶数のみを取り出し、昇順に並べ替えて、3で割った余りに変換」を表しています。(あまり意味がない処理ですが、簡潔で良い例が思いつかず…)
「なんとなくSQLっぽい」という雰囲気は伝わるでしょうか。LINQというのはデータソース(この場合は IEnumerable<int>型の sequence)に対して発行するクエリという概念を言語に組み込んでしまおう(Language Integrated)というコンセプトなのです。LINQ to SQL においては「まさにクエリ」という感じなのでしょうけど、上で書いたようにウチの業務ではデータベースはやりませんからクエリというのは直観に合いません。「クエリ」という言葉に惑わされないようにして下さい。単に IEnumerable<T> で表される列を操作するための機能セットです。
(B)のクエリ式というのは、LINQ専用に C# に組み込まれた特別な文法です。これぞ "Language Integrated" という感じですね。しかし、私はこのクエリ式を使うことは殆どなく、ほぼ100% (A)のメソッドチェイン形式を使っています。クエリ式はあまりにSQLに寄せすぎていての他の文法から浮いているように感じますし、結局のところメソッドチェイン形式のほうが汎用性が高いのです。ですから (B) は覚えなくていいです。
…ということはですね、覚えて欲しい部分は
- データベースはやらないので「クエリ」ではない
- クエリ式は使わないので "Languate Integrated ではない
というわけで「もはやLINQではない…」という感じなのですが、そうはいいつつ using System.Linq は必要ですし他に呼びようもないので仕方なく LINQ と呼んでいます。
では改めて (A) を見てみましょう。理解するためのポイントを幾つか挙げておきます。
- 既に上で説明した「ラムダ式」が幾つか見つかりますね。ラムダ式あってのLINQ、LINQあってのラムダ式。この2つは切り離せません。
- Where(), OrderBy(), Select() はいずれも「IEnumerable<T> を受け取って IEnumerable<T> を返す関数」です。
- Where(), OrderBy(), Select() は「拡張メソッド」として定義されています。拡張メソッドについても調べてみましょう。
到底全ては説明しきれませんが、「ハマりやすい落とし穴」を避ける情報は伝えたつもりです。あとはウェブや書籍で学習してみてください。